Info
This document is a work in progress and will be updated regularly.
Introduction
Scheduling a task graph on networked computers is a fundamental problem in distributed computing. Essentially, the goal is to assign computational tasks to different compute nodes in such a way that minimizes/maximizes some performance metric (e.g., total execution time, energy consumption, throughput, etc.).
We will focus on the task scheduling problem concerning heterogeneous task graphs and compute networks with the objective of minimizing makespan (total execution time) under the related machines model1.
It is common to model distributed applications as task graphs, where nodes represent computational tasks and directed edges represent precedence constraints and the flow of input/output data. As a result, task scheduling pops up all over the place - from machine learning and scientific workflows, to IoT/edge computing applications, to data processing pipelines used all over industry.
Figure 1 depicts a scientific workflow application used by Caltech astronomers to generate science-grade mosaics from astronomical imagery2.
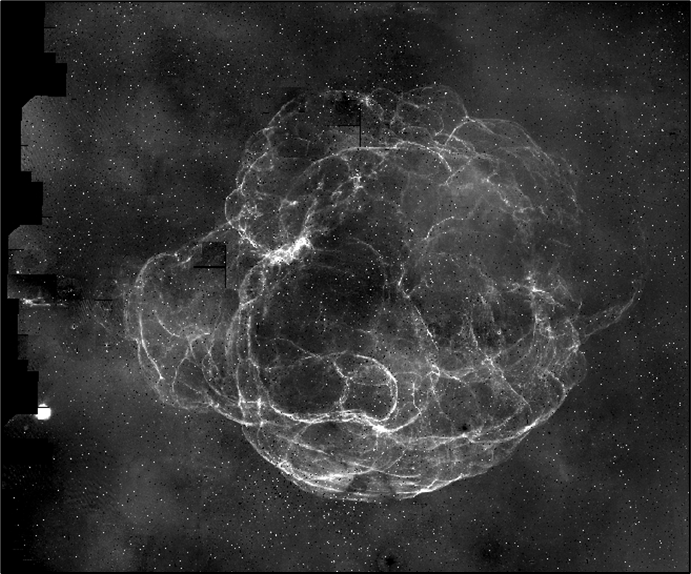 Figure 1a: Montage astronomical image
Figure 1a: Montage astronomical image
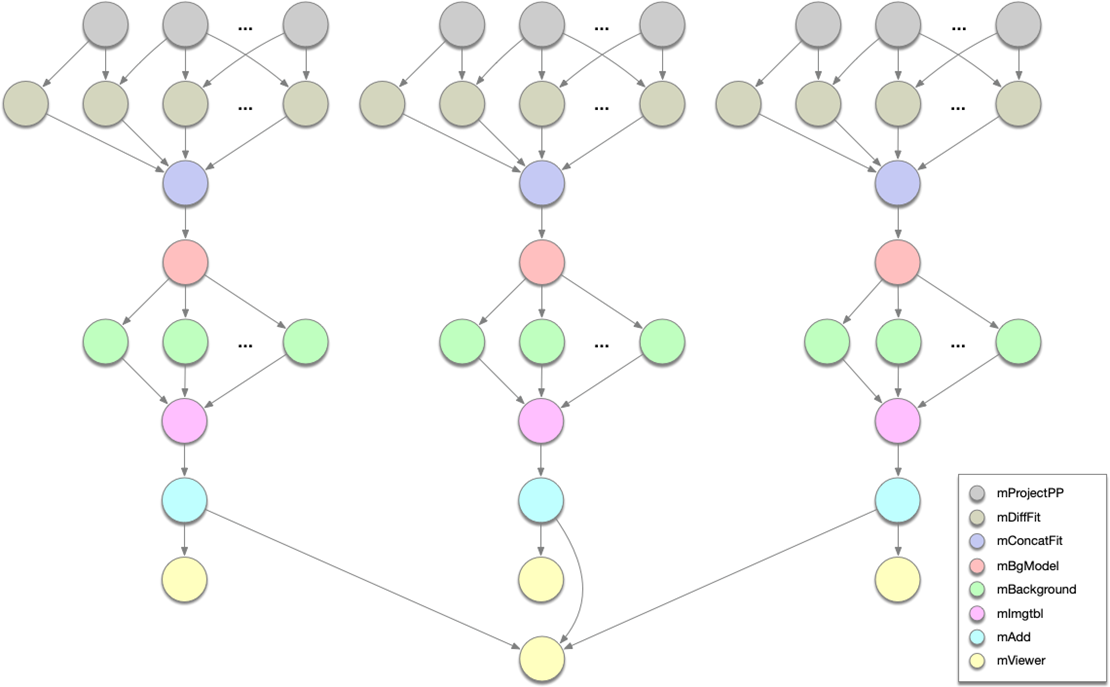 Figure 1b: Montage scientific workflow structure
Figure 1b: Montage scientific workflow structure
Problem Definition
Let us denote the task graph as , where is the set of tasks and contains the directed edges or dependencies between these tasks. An edge implies that the output from task is required input for task . Thus, task cannot start executing until it has received the output of task . This is often referred to as a precedence constraint.
For a given task , its compute cost is represented by and the size of the data exchanged between two dependent tasks, , is .
Let denote the compute node network, where is a complete undirected graph. is the set of nodes and is the set of edges. The compute speed of a node is and the communication strength between nodes is .
Under the related machines model3, the execution time of a task on a node is , and the data communication time between tasks from node to node (i.e., executes on and executes on ) is .
The goal is to schedule the tasks on different compute nodes in such a way that minimizes the makespan (total execution time) of the task graph.
Let denote a task scheduling algorithm. Given a problem instance which represents a network/task graph pair, let denote the schedule produced by for . A schedule is a mapping from each task to a triple where is the node on which the task is scheduled, is the start time, and is the end time.
A valid schedule must satisfy the following properties:
-
All tasks must be scheduled: for all , must exist such that and .
-
All tasks must have valid start and end times:
-
Only one task can be scheduled on a node at a time (i.e., their start/end times cannot overlap):
-
A task cannot start executing until all of its dependencies have finished executing and their outputs have been received at the node on which the task is scheduled:
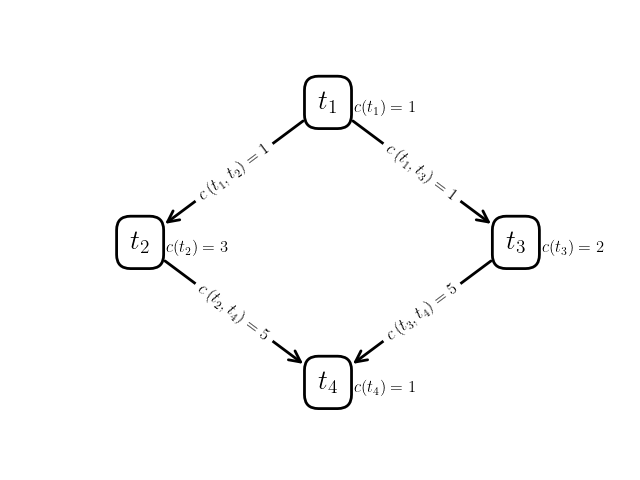 Figure 2a: Example task graph
Figure 2a: Example task graph
 Figure 2b: Example compute network
Figure 2b: Example compute network
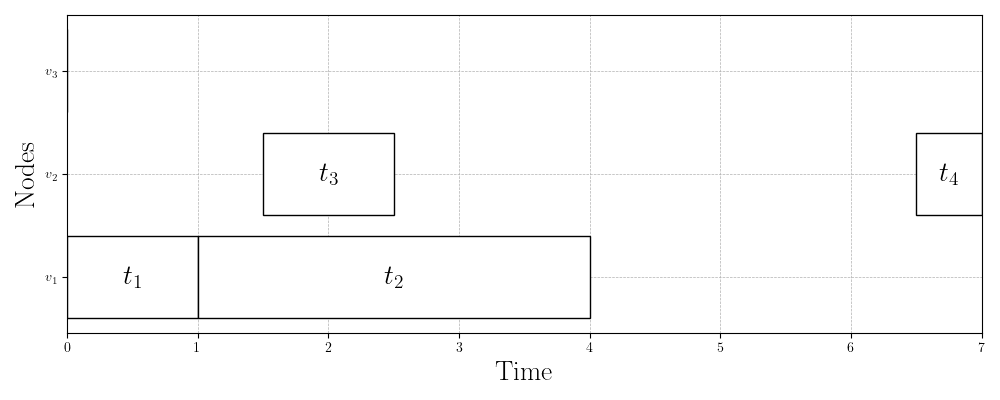 Figure 2c: Example schedule (Gantt chart)
Figure 2c: Example schedule (Gantt chart)
We define the makespan of the schedule as the time at which the last task finishes executing:
Example 1
Take a look at the task graph, network, and schedule in Figure 2. Let us start by verifying that this is a valid schedule for the problem instance (network/task graph pair).
First, task is scheduled to run on node . Clearly this is valid, since has no dependencies. When finishes running at time , which is valid since the cost of task is and the speed of node is ().
Then, immediately starts running at time on node . Again, this is clearly valid since there is no communication delay in sending the outputs from task to another node before running task .
Task , on the other hand, is scheduled to run on node . In this case, unit of output data from task must be sent to node as input data to task . The communication link between nodes and is , so this communication takes units of time. Thus, the start time of task is valid since it is exactly units of time after task terminates.
It’s easy to verify that tasks and have valid runtimes according to their costs and the speeds of the nodes they’re running on.
Finally, task is scheduled to run on node . Before it can start running, though, the units of output data from task must be sent from node to node over a communication link of strength . Thus, the start time of task is correct ( units of time after task ‘s finish time).
Thus, the schedule in Figure 2c is valid and has a makespan of .
The HEFT Scheduling Algorithm
This task scheduling problem has long been known to be NP-Hard and was recently shown to also be not polynomial-time approximable within a constant factor4. As a result, many heuristic algorithms that aren’t guaranteed to produce an optimal schedule but that, in practice, have been shown to work reasonably well have been proposed over the past decades.
One of the most commonly used of these algorithms is HEFT (Heterogeneous Earliest Finish Time)5. HEFT is a list-scheduling algorithm, which essentially means it first computes priorities for each of the tasks in the task graph and then schedules the tasks greedily in order of their priority on the “best” node (the one that minimizes the task’s finish time, given previously scheduled tasks).
Here is a summary of the algorithm:
-
Calculate average compute times for each task:
-
Calculate average communication times for each dependency:
-
Calculate the upward rank of each task (recursively):
-
In descending order of task upward ranks, greedily schedule each task on the node that minimizes its earliest possible finish time given previously scheduled tasks.
HEFT Example Calculations
| Task | |
|---|---|
| 2/3 | |
| 2 | |
| 4/3 | |
| 2/3 |
Table 1: Average compute times for each task
| 2/3 | |
| 2/3 | |
| 10/3 | |
| 10/3 |
Table 2: Average communication times for each dependency
| Task | |
|---|---|
| 22/3 | |
| 6 | |
| 16/3 | |
| 2/3 |
Table 3: Upward rank of each task
Figure 3 shows three valid schedules for the same problem instance. Figure 3a shows the first schedule we validated in the previous section with makespan . Figure 3b shows the schedule that the HEFT algorithm produces with a slightly better makespan of . Finally, Figure 3c shows the best schedule for this problem instance, which has a makespan of just . This is almost half the makespan of the schedule that HEFT (one of the most widely used scheduling algorithms) produces!
Figure 3a: Initial schedule (makespan = 7)
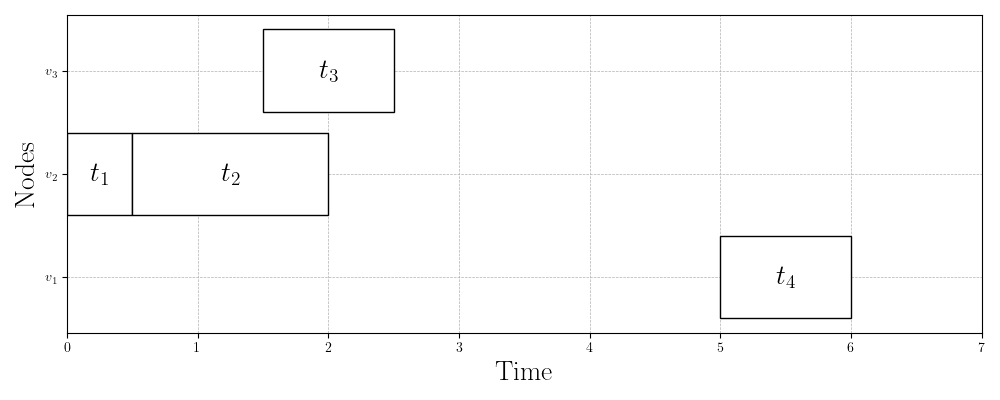 Figure 3b: HEFT schedule (makespan = 6)
Figure 3b: HEFT schedule (makespan = 6)
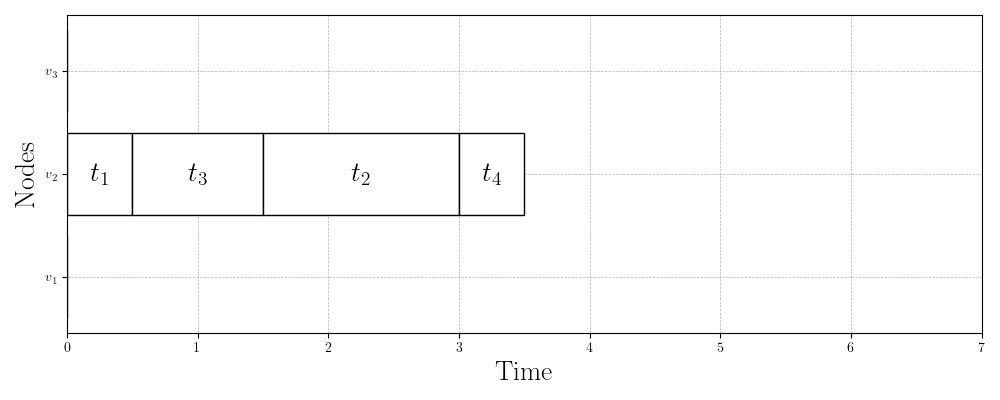 Figure 3c: Optimal schedule (makespan = 3.5)
Figure 3c: Optimal schedule (makespan = 3.5)
Questions to Consider
- Upward rank has the important property that a task’s upward rank is always greater than the upward rank of its dependent tasks. Why is this important?
- What is the runtime of HEFT in terms of , , , and ?
- Why does HEFT perform poorly on the problem instance in Figure 2? Can you think of an algorithm that would do better?
My Research Interests
Task scheduling is a fundamental problem in computer science that pops up everywhere. In this lecture, we formalized the task scheduling problem for heterogeneous task graphs and compute networks with the objective of minimizing makespan (total execution time) under the related machines model. Many other interesting variants of the task scheduling problem exist (see6).
We also learned HEFT, one of the most popular task scheduling heuristic algorithms, and saw a problem instance on which it performs rather poorly. Hundreds of heuristic algorithms have been proposed in the literature over the past decades (7 has nice descriptions of eleven scheduling algorithms). Due to their reliance on heuristics (since the problem is NP-Hard), all of these algorithms have problem instances on which they perform very poorly.
The performance boundaries between heuristic algorithms are not well-understood, however. This is an area of my research. We look at methodologies for comparing task scheduling algorithms to better understand the conditions under which they perform well and poorly.
Figures 4 and 5 depict results from our efforts in this area. Figure 4 shows benchmarking results for 15 scheduling algorithms on 16 datasets. The color represents the maximum makespan ratio (MMR) of an algorithm on a problem instance in a given dataset. The MMR of an algorithm is essentially how many times worse the algorithm performs on a particular problem instance compared to the other scheduling algorithms. For example, on some problem instances in the cycles dataset, the BIL algorithm performs more than five times worse than another one of the 15 algorithms! On other problem instances in the same dataset, however, the algorithm performs well (MMR=1).
Figure 5 shows results from our own comparison method that pits algorithms against each other and tries to find a problem instance where one algorithm maximally underperforms compared to another. Our hope is that by identifying these kinds of problem instances, we can better understand the conditions under which algorithms perform well/poorly.
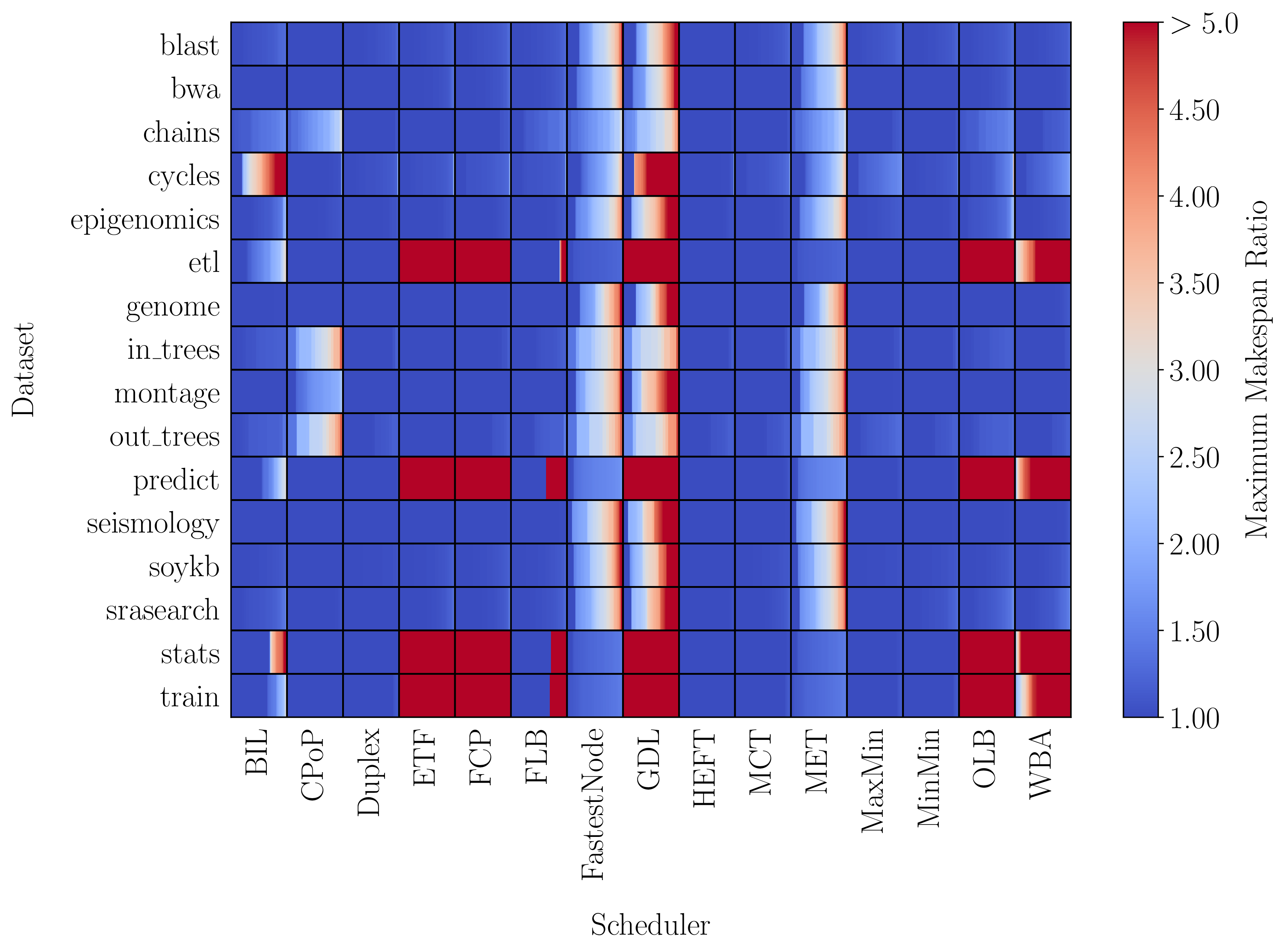 Figure 4: Benchmarking results for 15 scheduling algorithms on 16 datasets
Figure 4: Benchmarking results for 15 scheduling algorithms on 16 datasets
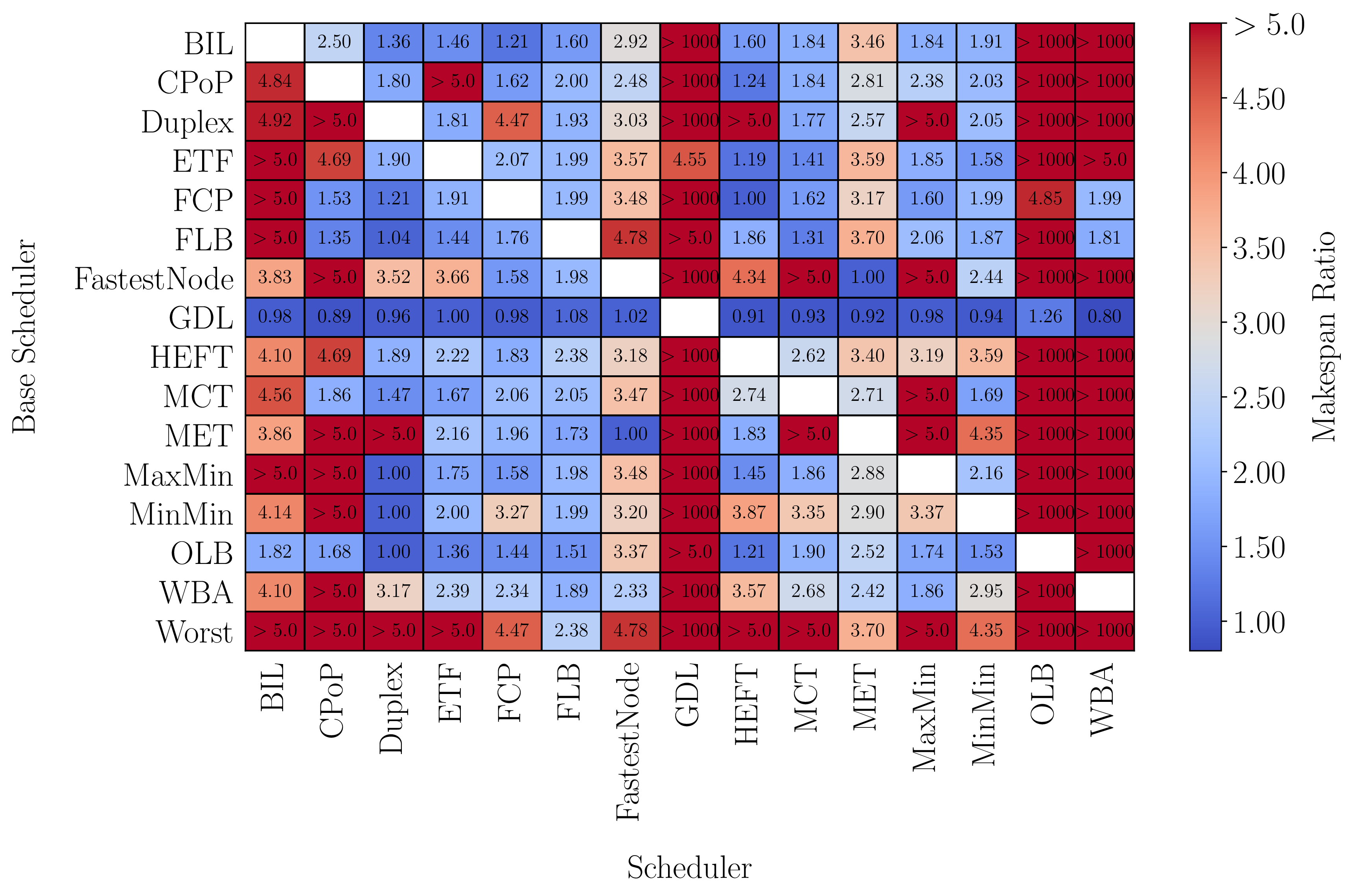 Figure 5: Adversarial analysis results for 15 scheduling algorithms
Figure 5: Adversarial analysis results for 15 scheduling algorithms
Theory
Scheduling Algorithms
Surveys and Algorithm Comparison Papers
Machine Learning Approaches
Data and Other References
Footnotes
-
M. Rynge et al. 2014. “Producing an Infrared Multiwavelength Galactic Plane Atlas Using Montage, Pegasus, and Amazon Web Services.” In Astronomical Data Analysis Software and Systems XXIII, 211. ↩
-
R. L. Graham. 1969. “Bounds on Multiprocessing Timing Anomalies.” SIAM Journal on Applied Mathematics 17(2): 416-429. DOI: 10.1137/0117039 ↩
-
Abbas Bazzi and Ashkan Norouzi-Fard. 2015. “Towards Tight Lower Bounds for Scheduling Problems.” In Algorithms - ESA 2015, 118-129. DOI: 10.1007/978-3-662-48350-3_11 ↩
-
Haluk Topcuoglu, Salim Hariri, and Min-You Wu. 1999. “Task Scheduling Algorithms for Heterogeneous Processors.” In 8th Heterogeneous Computing Workshop, 3-14. DOI: 10.1109/HCW.1999.765092 ↩
-
R.L. Graham, E.L. Lawler, J.K. Lenstra, and A.H.G. Rinnooy Kan. 1979. “Optimization and Approximation in Deterministic Sequencing and Scheduling: a Survey.” In Discrete Optimization II, Annals of Discrete Mathematics 5: 287-326. DOI: 10.1016/S0167-5060(08)70356-X ↩
-
Tracy D. Braun et al. 2001. “A Comparison of Eleven Static Heuristics for Mapping a Class of Independent Tasks onto Heterogeneous Distributed Computing Systems.” Journal of Parallel and Distributed Computing 61(6): 810-837. DOI: 10.1006/jpdc.2000.1714 ↩